本文基于OWASP最新发布的《OWASP Top 10 for Agentic Application 2026》总结了面向智能体的十大安全威胁的定义、脆弱性分析和防御措施(附录1), 同时阐述了与 《OWASP Top 10 LLM 2025》、《OWASP Agentic AI威胁与防护框架》的映射关系(附录2)。
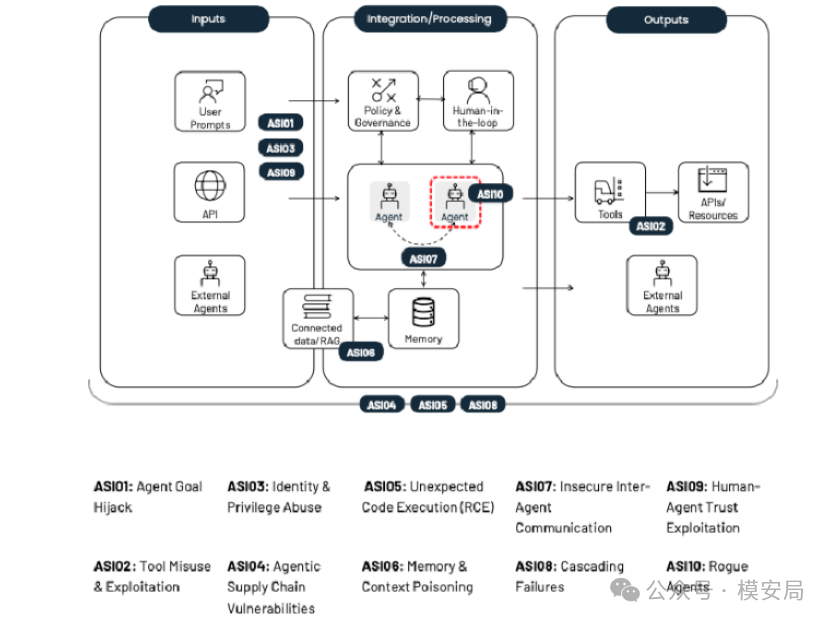
攻击者通过操纵智能体的委派关系、上下文或 Agent-to-Agent 通信,使智能体继承、缓存或冒用本不应拥有的身份与权限,从而执行越权操作。这类风险一般发生在身份管理与权限委派层。
当智能体凭证被写入上下文或长期记忆后,权限滥用还可能跨任务、跨会话持续存在。
攻击者通过投毒、篡改或伪装智能体依赖的外部组件(如模型、工具、插件、Prompt 模板、Agent 描述文件或注册服务),在不直接攻击智能体本身的情况下影响其行为。这类风险一般发生在组件加载与依赖管理层。
由于 Agentic 系统中的组件往往在运行时动态发现和加载,被污染的组件可能被多个智能体同时信任,从而快速扩散影响。
与传统软件供应链相比,该风险不仅涉及代码,还包括 Prompt、配置和行为描述等“软逻辑”。
攻击者通过提示注入、上下文操纵或工具链缺陷,使智能体生成或处理的文本被直接或间接解释为可执行代码,从而触发非预期的代码执行。这类风险一般发生在代码生成与执行边界处。
在自动化编程、运维或自修复场景中,智能体可能在缺乏人工审查的情况下执行生成代码,导致远程代码执行、数据破坏或系统失控。
该风险属于语言到行为边界失效所引发的高危问题。
攻击者通过输入、外部数据或智能体交互,将错误、恶意或误导性信息写入智能体的长期记忆或可复用上下文中,影响其后续决策与行为。这类风险一般发生在记忆管理与上下文复用层。
与一次性 Prompt Injection 不同,被污染的记忆会在未来多次任务中反复生效,具有持续性和累积性。
在向量检索或跨租户记忆共享场景中,该风险还可能引发数据隔离问题。
攻击者通过伪造、篡改或重放智能体之间的通信消息,操纵其协作行为或决策结果。这类风险一般发生在Agent-to-Agent 通信层。
由于智能体间通信通常被视为“内部可信流量”,一旦缺乏身份验证、完整性校验或防重放机制,攻击者即可插入恶意指令而不易被发现。
该风险在多智能体协作、自动调度和分布式决策场景中尤为突出。
攻击者或系统错误触发的单一异常,在自治执行与多智能体协作机制下被不断复制和放大,最终演变为系统级连锁故障。这类风险一般发生在自动执行与协作传播层。
规划错误、被污染的记忆或错误的工具调用结果,可能被后续智能体视为可信输入,从而反复执行。
该风险不依赖新的攻击手段,而是源于 Agentic 系统的放大效应。
攻击者通过操纵智能体的输出内容,使其以权威、紧急或高度合理的方式影响人类判断,从而诱导人类执行高风险操作。这类风险一般发生在人机交互层。
在此场景下,最终操作由人类完成,但决策过程已被误导,传统的自动化安全控制难以生效。
该风险表明,“人在回路”并不必然等同于安全。
智能体因目标漂移、奖励机制缺陷、上下文污染或持续操纵,逐渐偏离原始设计意图并执行非预期行为。这类风险一般发生在长期运行与生命周期管理层。
失控智能体的单次行为可能看似合理,但整体行为模式已不符合系统目标或安全约束。
在多智能体环境中,多个失控智能体可能相互强化,导致系统难以及时恢复控制。
附录1:OWASP Top 10 Agentic Applications-2026
安全风险与防护策略清单
智能体目标劫持 | 2. 外部通信渠道劫持 3. 恶意提示覆盖 4. 指令覆盖导致欺诈信息 | 2. 最小化影响与最小权限 3. 锁定系统提示词 4. 运行时意图验证 5. 使用“意图胶囊” 6. 数据源消毒 (CDR/过滤) 7. 全面监控与建立行为基线 8. 定期红队测试 9. 纳入内部威胁计划 |
工具滥用与利用 | 2. 工具访问范围过大 3. 未经验证的输入转发 4. 不安全浏览或联合调用 5. 循环放大攻击 6. 外部数据工具中毒 | 2. 操作级认证与审批 3. 沙箱执行与出口控制 4. 策略执行中间件 (“意图关卡”) 5. 自适应工具预算 6. 即时与临时访问 7. 语义与身份验证 (“语义防火墙”) 8. 全面日志、监控与漂移检测 |
身份与权限滥用 | 2. 基于记忆的权限保留与数据泄露 3. 跨代理信任利用 (困惑副手) 4. 工作流中的TOCTOU问题 5. 合成身份注入 | 2. 隔离身份与上下文 3. 强制操作级授权 4. 权限提升需人工介入 5. 定义并绑定意图 6. 采用代理身份管理平台 7. 绑定权限四要素 8. 检测委托与传递权限 9. 检测异常提权行为 |
智能体供应链风险 | 2. 工具描述符注入 3. 仿冒与抢注攻击 4. 脆弱的第三方代理 5. 受陷的MCP/注册服务器 6. 中毒知识插件 | 2. 依赖项把关 3. 容器化与构建安全 4. 保护提示与内存 5. 代理间通信安全 6. 持续验证与监控 7. 固定与分级部署 8. 供应链“急停”开关 9. 零信任应用设计 |
以外代码执行 | 2. 恶意或可利用的代码幻觉 3. 反射提示调用Shell命令 4. 不安全的函数调用或反序列化 5. 暴露的、未净化的eval()函数 6. 未验证或恶意的包安装 | 2. 隔离预生产检查 3. 禁止生产环境eval 4. 执行环境安全 (沙箱/非root) 5. 架构隔离与设计 6. 访问控制与审批 7. 代码分析与监控 |
记忆与上下文投毒 | 2. 共享用户上下文污染 3. 上下文窗口操纵 4. 长期记忆漂移 5. 系统性错位与后门 6. 跨代理传播 | 2. 内容验证 3. 内存分段 4. 访问与留存限制 5. 来源追溯与异常检测 6. 防止自输出重复吸纳 7. 韧性建设与验证 8. 未验证记忆过期 9. 按信任度加权检索 |
智能体间通信不安全 | 2. 消息篡改导致跨上下文污染 3. 信任链重放攻击 4. 协议降级与描述符伪造 5. 消息路由攻击 6. 用于行为剖析的元数据分析 | 2. 消息完整性与语义保护 3. 代理感知防重放 4. 协议与能力安全 5. 限制基于元数据的推断 6. 协议固定与版本强制 7. 发现与路由保护 8. 认证注册与代理验证 9. 类型化合约与模式验证 |
级联失败 | 2. 损坏的持久性记忆 3. 中毒消息引发的代理间级联 4. 级联的工具滥用与权限提升 5. 污染更新引发的自动部署级联 6. 治理漂移级联 7. 反馈循环放大 | 2. 隔离与信任边界 3. 即时工具访问与运行时检查 4. 独立策略执行 5. 输出验证与人工审核点 6. 速率限制与监控 7. 实施爆炸半径护栏 8. 行为与治理漂移检测 9. 数字孪生回放与策略门控 10. 日志记录与不可否认性 |
人机信任滥用 | 2. 敏感操作缺少确认 3. 情感操控 4. 虚假解释性 | 2. 不可变日志 3. 行为检测 4. 允许报告可疑交互 5. 自适应信任校准 6. 内容来源与策略执行 7. 隔离预览与影响 8. 人因与UI防护 9. 计划偏离检测 |
失控智能体 | 2. 工作流劫持 3. 共谋与自我复制 4. 奖励破解与优化滥用 | 2. 隔离与边界 3. 监控与检测 4. 遏制与响应 5. 身份认证与行为完整性强制 6. 要求定期行为认证 7. 恢复与重集成 |
附录2:三大AI风险框架映射表
智能体目标劫持 | LLM06:2025 过度代理 | T7 不一致与欺骗行为 |
工具滥用与利用 | T4 资源过载 T16 不安全的代理间协议滥用 | |
身份与权限滥用 | LLM06:2025 过度代理 LLM02:2025 敏感信息泄露 | |
智能体供应链风险 | T2 工具滥用 T11 意外的远程代码执行与代码攻击 T12 代理通信中毒 T13 恶意代理 T16 不安全的代理间协议滥用 | |
以外代码执行 | LLM05:2025 不当输出处理 | |
记忆与上下文投毒 | LLM04:2025 模型数据投毒 LLM08:2025 向量与嵌入漏洞 | T4 资源超载 T6 目标破坏 T12 共享记忆投毒 |
智能体间通信不安全 | LLM06:2025 过度代理 | T16 不安全的代理间协议滥用 |
级联失败 | LLM04:2025 模型数据投毒 LLM06:2025 过度代理 | T8 否认与不可追溯性 |
人机信任滥用 | LLM05:2025 不当输出处理 LLM06:2025 过度代理 LLM09:2025 信息误导 | T8 否认与不可追溯性 T10 超载人类决策环 |
失控智能体 | LLM09:2025 信息误导 | T14 针对多代理系统的人类攻击 T15 人类操纵 |
信息来源:管铭 模安局


