软件安全中的大型语言模型:漏洞检测技术与研究洞见综述
本次介绍的综述论文 《LLMs in Software Security: A Survey of Vulnerability Detection Techniques and Insights》发表在CSUR 2025上,来自Texas A&M University等科研团队的研究工作。
大型语言模型(Large Language Models, LLMs)正逐渐成为软件漏洞检测领域的变革性工具。传统方法(包括静态分析和动态分析)在效率、误报率以及应对现代软件复杂性方面存在局限。LLMs 通过代码结构分析、模式识别以及修复建议生成,为漏洞缓解提供了一种全新的思路。
本文综述了 LLM 在漏洞检测中的研究进展,系统分析了问题建模、模型选择、应用方法、数据集以及评测指标。本文进一步探讨了当前研究面临的挑战,重点关注跨语言检测、多模态融合以及仓库级分析等方向。基于研究发现,本文提出了针对数据集可扩展性、模型可解释性以及低资源场景的潜在解决方案。
本文的主要贡献包括:(1)系统分析 LLM 在漏洞检测中的应用现状;(2)提出一个统一框架,以梳理不同研究间的模式与差异;(3)总结关键挑战与未来研究方向。本文旨在推动对基于 LLM 的漏洞检测技术的深入理解。
最新研究成果可在 https://github.com/OwenSanzas/LLM-For-Vulnerability-Detection 获取。
研究背景
一些常见的漏洞数据库,如 Common Weakness Enumeration (CWE)、Common Vulnerabilities and Exposures (CVE)、Common Vulnerability Scoring System (CVSS) 以及 National Vulnerability Database (NVD),被广泛用于记录和评估常见的软件漏洞。
CWE(通用弱点枚举)关注的是软件开发生命周期中的所有漏洞(从开发到维护阶段)。与其关注具体的现实安全漏洞(如 Heartbleed 或 Log4Shell),CWE 更注重这些漏洞的根本原因,例如 Use-After-Free(CWE-416) 和 Out-of-Bounds Write(CWE-787)。
CVE(通用漏洞与暴露)是一个公共社区项目,用于识别和编目软件与硬件中的安全漏洞。社区会为每个现实中的漏洞分配一个唯一的标识符。例如,Log4Shell 的标识符为 CVE-2021-44228。
CVSS(通用漏洞评分系统)是一种标准化的漏洞风险评估框架,它通过多个指标(如可利用性、影响程度、漏洞利用代码的成熟度以及修复难度等)来评估漏洞的风险等级。这些指标综合得出一个 0 到 10 的评分,并根据得分划分漏洞严重程度(从低到严重)。例如,Log4Shell 的 CVSS 得分为 10 分(严重等级:Critical)。
NVD(国家漏洞数据库)是一个包含现实漏洞基础信息的数据库,其中包括 CVE 标识符、漏洞的技术细节、CVSS 评分以及修复建议等。例如,NVD 记录显示 Log4Shell 可通过构造恶意的 JNDI 语句在受害服务器上远程执行代码,该漏洞的根本原因是 输入验证不当(CWE-20) 和 资源消耗未受控(CWE-400)。
漏洞检测是本文综述中所有选定论文的核心研究重点,也是大型语言模型(LLMs)在软件安全领域的主要应用方向。其基本任务可以形式化地定义为一个二分类问题:设输入源代码为 ??,LLM 驱动的漏洞检测器为 ???。输出结果 ?? ∈ {0, 1} 表示漏洞状态,其中 ?? = 1 表示代码存在漏洞,?? = 0 表示代码无漏洞。图 3 展示了大多数研究中漏洞检测任务的典型工作流程。
除了二分类检测之外,一些研究进一步探索了 LLMs 在多类别漏洞分类任务中的能力,以提升模型的可靠性。该任务要求 LLM 不仅能够判断代码中是否存在漏洞,还需要根据既定标准(如 CWE)确定其具体漏洞类型。形式化定义如下:设输入源代码为 ??,LLM 驱动的漏洞分类器为 ???。输出结果 ?? 表示具体的漏洞类型。例如,当分析一段代码时,LLM 不仅可以检测到其存在漏洞,还能够将其分类为 “CWE-79:跨站脚本攻击(XSS)”,从而为安全修复提供更具体的指导。
一些研究将漏洞分析的范围进一步扩展到漏洞严重程度预测(severity prediction),与检测任务相结合。该任务可被建模为多类别分类问题或回归问题,具体取决于严重程度的度量粒度。
形式化定义如下:设输入源代码为 ??,LLM 驱动的严重性预测器为 ???。输出结果 ?? 可有两种形式:它可以表示漏洞严重程度的分类结果(如 low、medium、high),或具体的数值评分,用于量化输入源代码 ?? 的漏洞严重程度。
不同研究在严重性预测上采用了不同方法:
类别分类(Categorical Classification):Alam 等人采用三级分类体系(高、中、低)进行直观的漏洞严重性评估。
数值评分预测(Score Prediction):Fu 等人要求 LLM 预测漏洞的数值化 CVSS 分数(范围为 0–10),以提供更精确的严重性衡量。
这种附加的严重性信息有助于在实际应用中优先安排漏洞修复工作,并更有效地分配安全资源。
综述分析
Q1:哪些大型语言模型(LLMs)已被应用于漏洞检测?
仅编码器(Encoder-only)LLMs。
仅编码器的 LLM 仅使用 Transformer 模型的编码器部分。这类模型专为分析和表示代码或语言上下文而设计,而非生成输出序列,非常适合需要深入理解语法和语义的任务。通过注意力机制,这些模型能够将输入序列编码为结构化表示,从而捕捉关键的语法与语义信息。在软件工程领域,典型的仅编码器模型包括 CodeBERT、GraphCodeBERT、CuBERT、VulBERTa、CCBERT、SOBERT 和 BERTOverflow 等。
编码器–解码器(Encoder-Decoder)LLMs。
编码器–解码器模型结合了 Transformer 的编码器与解码器组件,使其能够同时处理理解与生成任务。编码器将输入序列转换为结构化表示,随后解码器将其转化为输出序列。这种结构使模型在翻译、摘要、转换文本或代码等任务中具有高度的灵活性。代表性模型包括 PLBART、T5、CodeT5、UniXcoder 和 NatGen 等。
仅解码器(Decoder-only)LLMs。
仅解码器的 LLM 仅使用 Transformer 架构中的解码器部分,用于根据输入提示生成文本或代码。该结构利用模型的上下文理解与扩展能力,通过逐步预测后续 token 来生成复杂且连贯的序列。这类模型常用于以生成为核心的任务,如漏洞检测与代码补全等,擅长在代码中识别潜在的模式与问题。代表性模型包括 GPT 系列(GPT-2、GPT-3、GPT-3.5、GPT-4),以及专门面向软件工程领域的模型,如 CodeGPT、Codex、Polycoder、Incoder、CodeGen 系列、Copilot、Code Llama 和 StarCoder 等。
结论:近年来的研究趋势显示,漏洞检测领域正从仅编码器模型逐渐转向采用 GPT、CodeLlama 等大型仅解码器架构的模型。尽管仅编码器模型仍在非微调类研究中占主导地位(约占 72.4%),但在微调实验中,仅解码器模型已占据约 65% 的比例。与此同时,仅编码器与编码器–解码器架构正逐渐被更多研究用作对比基线模型(baseline models)。
RQ2:为评估漏洞检测设计了哪些基准、数据集和评测指标?
表 3 显示了不同软件系统中漏洞分布的一些有趣规律。操作系统(如 Android、MacOS X、Linux 内核 和 Windows Server)在漏洞数量上占据主导,其次是 网页浏览器(如 Chrome 和 Firefox)以及 开发平台(如 GitLab)。根据 CVE 统计,过去五年中内存相关漏洞是最常见的漏洞类型。由于 C/C++ 是广泛使用但内存安全性不足的编程语言,因此其导致的内存破坏漏洞数量较多,使得漏洞检测变得愈发紧迫。
基于对 56 篇选定论文的分析,本文统计了所有研究中涉及的目标编程语言,其分布如图 5 所示。
结论:研究领域中,目标编程语言的分布呈现明显差异:C/C++ 占据主导地位,占研究总量的 50%,其次是 Java 占 21.1%。Solidity 占 11.8%,主要因为其在智能合约和金融交易中的关键作用。其余 16.6% 涉及其他编程语言,包括 Python、PHP 和 Go 等。
函数级(Function-level):此类数据集中的每条数据通常包含以下属性:函数实现(通常包括漏洞前后的实现)、漏洞标记(通常 1 表示存在漏洞,0 表示无漏洞)。常用的数据集包括 BigVul 和 Devign(也称 FFmpeg 与 QEMU 数据集)。这类数据集常用于对大型模型进行微调,以及评估 LLM 检测漏洞的能力,但在实际应用中价值有限,因为现实世界中的漏洞通常涉及跨文件的多个函数。
文件级(File-level):一些数据集不仅以函数为单位,还按文件组织,如 Juliet C/C++ 和 Juliet Java 测试套件。Juliet 测试套件中的部分漏洞在结构上高度模拟现实世界漏洞,包括跨文件函数调用或跨文件访问全局变量等复杂上下文。这类复杂漏洞对 LLM 的检测能力提出了较高挑战。以 Juliet C/C++ 测试套件为例,测试用例 501129 中,漏洞所在的文件和行已在跟踪中标出,为 LLM 提供了检测跨文件漏洞的线索,同时也提示需要提升模型的跨文件检测能力。
提交级(Commit-level):许多开源软件在 GitHub 上通过提交 commit 修改源代码。即便是可信维护者,也可能提交包含恶意修改的 commit,从而使目标软件存在漏洞。因此,对每次提交进行漏洞检测也是必要的。典型的 commit 级数据集包括 CVEfixes 和 Pan2023。这些数据集通常包含仓库 URL、commit 哈希(唯一标识每次提交)、diff 文件(展示提交前后的差异)。LLM 可以分析提交前后的代码变化,判断该提交是否存在漏洞,并通过仓库 URL 获取上下文信息。
仓库级与应用级(Repository- and Application-level):这类数据集通常用于整个项目的漏洞检测。CWE-Bench-Java 是一个仓库级数据集,聚焦 Java 项目,每个仓库附带漏洞元数据,如 CWE ID、CVE ID、修复提交和漏洞版本,使分析和验证更系统可靠。Ghera 是一个应用级数据集,每条数据包含三个应用:一个包含漏洞 X 的易受攻击应用、一个可利用漏洞 X 攻击该应用的恶意应用,以及一个没有漏洞 X 的安全应用。每条数据还附带构建和运行应用的指导,以演示漏洞及其利用情况,从而验证漏洞的存在与利用。
图 7 展示了一个 commit 级数据集的示例。
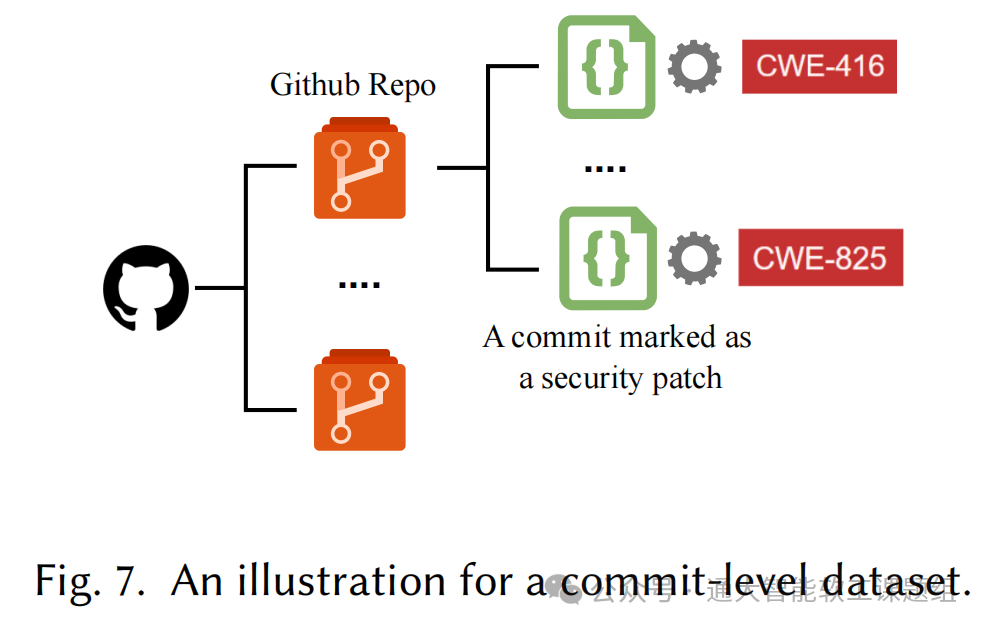
其他类型的数据集:随着区块链的发展,针对智能合约的数据集也被构建,如 FELLMVP,包含大量存在逻辑漏洞(如重入攻击、整数溢出/下溢)的智能合约(合约级)。一些数据集专注于特定漏洞类型。例如,Code Gadgets 仅关注 C/C++ 程序中的两类漏洞:缓冲区错误漏洞(CWE-119)和资源管理错误漏洞(CWE-399);SolidFi 仅针对注入漏洞。
结论:当前的漏洞数据集存在两个主要局限性:(1)语言不平衡 —— C/C++ 占比约 60%,占据主导地位,而 Java 尽管在企业和 Android 开发中被广泛使用,却缺乏完整的数据集支持。(2)覆盖范围不足 —— 缺乏能够反映现实开发场景的仓库级数据集,而现实中的漏洞通常跨越多个文件和依赖项。这种真实、大规模仓库数据集的缺乏成为 LLM 在实际漏洞检测应用中的一个关键限制。
基于 LLM 的漏洞检测系统评估需要使用多种指标,这些指标可分为三类:分类指标、生成指标和效率指标。
结论:分类指标(如准确率、精确率)被广泛采用,对于不平衡数据集通常使用 Matthews 相关系数(MCC)。生成指标(如 BLEU 和 ROUGE)用于评估生成描述的质量,而执行时间则用于衡量效率。
RQ3:LLMs 在漏洞检测中使用的技术有哪些?
当前,基于 LLM 的漏洞检测面临若干关键挑战:数据泄露(Data Leakage) —— 数据集可能包含训练数据与测试数据的重叠,导致模型性能指标被高估。复杂代码上下文理解困难 —— 对涉及多函数、多文件或跨依赖的复杂漏洞,模型难以准确捕捉上下文关系。大上下文窗口中的位置偏差(Positional Bias) —— 长序列输入可能导致重要信息丢失,影响漏洞检测的准确性。高误报率及零日漏洞检测能力不足 —— 模型在未知或新型漏洞(zero-day vulnerabilities)上的表现较差,误报率较高。
代码数据预处理(Code Data Preprocessing)
代码处理技术主要有两个目标:优化 LLM 有限上下文窗口的利用,提升处理效率;增强 LLM 对代码语义信息的理解,提高漏洞检测能力。
主要方法包括:
抽象语法树分析(Abstract Syntax Tree, AST)AST 提供程序结构的分层表示,将代码元素按语法关系组织成树状结构。这种结构化表示去除了非必要的语法细节,同时保留代码组件之间的语义关系。
数据/控制流分析(Data/Control Flow Analysis)AST 无法直接表示程序的数据流和控制流,因此一些研究采用 数据流图(DFG) 和 控制流图(CFG) 来帮助 LLM 理解跨过程的数据流与控制流关系。
检索增强生成(Retrieval-Augmented Generation, RAG)RAG 通过集成信息检索系统,为 LLM 提供额外的相关信息,从而增强模型的推理与检测能力。
程序切片(Program Slicing)通过程序切片技术删除与漏洞无关的代码行,仅保留与触发漏洞相关的关键代码行,提高检测聚焦度。
LLVM 中间表示(LLVM Intermediate Representation, IR)将源代码转换为 LLVM IR,使分析和检测方法无需针对不同编程语言进行特定适配,提高漏洞检测方法的通用性。LLVM IR 同时保留程序结构与语义,便于 LLM 分析代码中潜在的依赖关系。
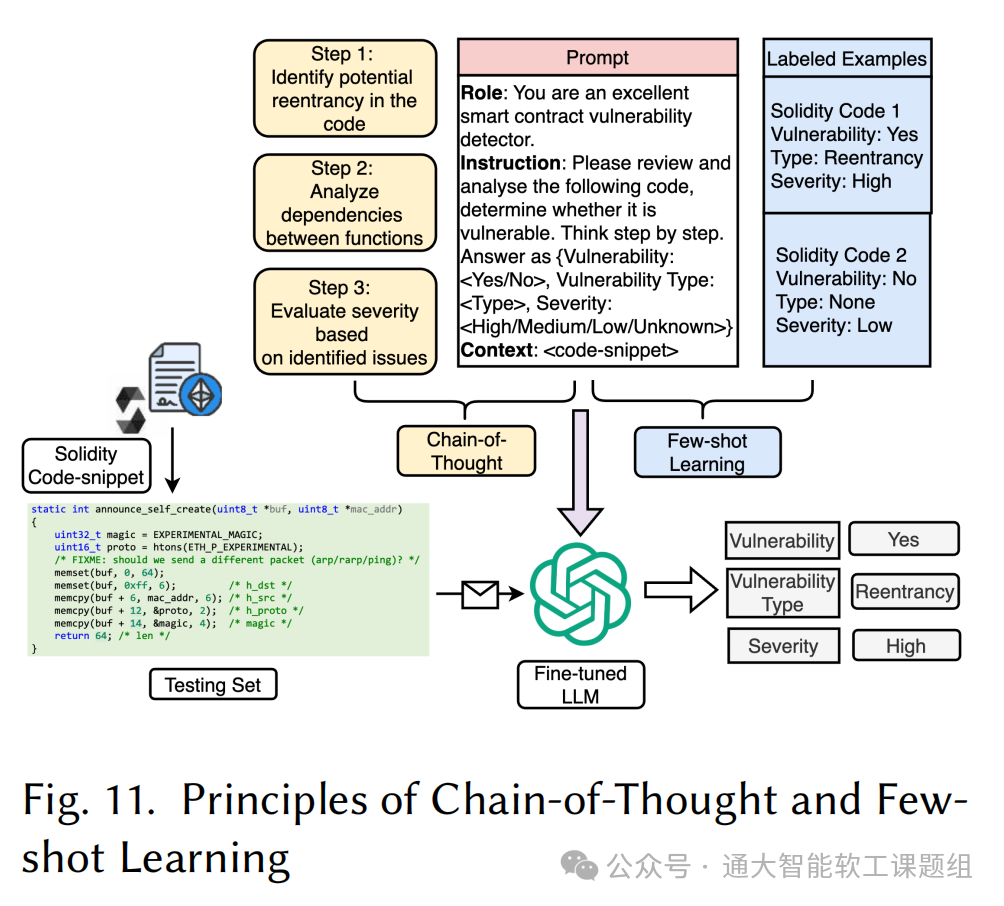
提示工程技术(Prompt Engineering Techniques)提示工程是优化基于 LLM 的漏洞检测系统的最常用策略之一,它通过定制输入提示(prompt)实现对模型输出的精确控制。主要方法包括:
思路链提示(Chain-of-Thought, CoT Prompting):引导 LLM 按照逐步指令进行推理,在生成最终输出前提高推理准确性。
少样本学习(Few-shot Learning, FSL)利用少量带标签的示例在提示中训练模型,以提升特定任务的性能。
分层上下文表示(Hierarchical Context Representation)用于处理大规模代码库时的上下文长度限制,将代码按模块、类、函数和语句层次组织。通过分层表示,LLM 可以在不同抽象层次上分析代码,从而更好地理解复杂结构。
多级提示(Multi-level Prompting)将漏洞检测任务拆分为多个提示,每个提示对应特定分析层级。相较于在单一提示中提供全部代码和任务,多级提示策略分阶段处理,提高检测精度。
多提示代理与模板(Multiple Prompt Agents and Templates)使用多个专门设计的提示代理,每个代理采用特定模板,在漏洞检测流程中承担不同角色。这种方法可以协同完成复杂任务,如漏洞识别、类型分类和修复建议生成。
微调(Fine-tuning)微调帮助大型语言模型(LLMs)更好地学习特定任务,通过在预训练模型基础上使用任务相关的新数据进行再训练。微调的重要性体现在三个方面:代码中的安全问题具有特定模式,LLM 需要学习这些模式才能准确识别漏洞;计算机代码与普通文本不同,LLM 需要学习如何更好地理解代码;漏洞检测要求高度准确,漏报或误报都可能带来严重后果。
微调方法主要包括:
全量微调(Full Fine-tuning, FFT):在训练过程中更新模型的所有参数。受计算资源限制,大多数研究使用参数少于 150 亿的模型,如 CodeT5、CodeBERT 和 UniXcoder。
参数高效微调(Parameter-Efficient Fine-tuning, PEFT):仅修改部分参数,其余预训练权重保持冻结状态,例如 LoRA 方法。
判别式微调(Discriminative Fine-tuning)
生成式微调(Generative Fine-tuning):支持序列到序列学习,用于生成结构化输出,如漏洞描述或易受攻击的代码行标识。
总结: LLM 漏洞检测技术,代码预处理:包括 AST 分析、数据/控制流分析、RAG 和程序切片等,可提升上下文利用率,但在处理复杂跨文件漏洞时仍有局限。提示工程:如 CoT prompting、少样本学习和专用代理等方法可提高准确率。大模型(>100 亿参数)更适合使用思路链方法,而小模型更适合简单提示。微调:全量或参数高效微调方法(如 LoRA)可在大模型上实现接近 0.9 的 F1 分数。随着模型能力的提升,其内在优势可能超过预处理带来的提升,因此未来研究需重点解决复杂上下文和跨文件漏洞检测问题。
RQ4:基于 LLM 的漏洞检测面临的挑战及潜在解决方向
挑战 1:研究问题范围有限
当前大部分研究仅关注判断单个代码片段是否存在漏洞。约 83% 的研究集中在孤立代码片段分析中,这种环境虽然便于评估,但无法反映实际开发场景的复杂性,如整个代码库分析或协作开发中出现的漏洞。
潜在方向:
(1)基于代码演进的研究问题
全量/增量检测:全量检测需分析跨多文件的整个代码库;增量检测关注新提交的代码。当前 LLM 更擅长孤立代码片段分析,难以处理更广泛上下文。
提交级检测:结合提交信息和静态分析,但遇到训练数据中未见的 API 时容易失效。
(2)基于漏洞报告流程的研究问题
漏洞复现:利用输入驱动(如模糊测试)生成可触发漏洞的测试用例,为漏洞检测提供证据,减少误报。
漏洞修复:实际项目中实现仍具挑战,修复需满足:通过所有测试、防止漏洞复现、不引入新漏洞。数据集质量和 LLM 能力限制了验证效果。
(3)基于漏洞特征的研究问题
专门化漏洞检测:LLM 在不同漏洞类型上的表现差异大,如对越界写入(CWE-787)检测效果高,而对缺失授权(CWE-862)效果差。
漏洞分类与严重性评估:准确分类(如 CWE 框架)和预测严重性影响修复优先级,现阶段仍存在困难。
挑战 2:漏洞语义表示复杂
漏洞模式通常非常复杂,如外部依赖、多函数调用、全局变量及复杂软件状态。大多数方法仍仅关注函数或文件级代码块,对大型项目帮助有限。
潜在方向:
(1)动态代码知识扩展:通过反馈机制和自适应方法,让 LLM 可自由访问和理解仓库代码,提供更广泛上下文,降低误报率。
(2)优化代码表示:利用 AST、CFG、DFG 等结构化表示减少 token 数量,同时未来可探索更复杂语义处理、多方法整合、上下文保留和混合图表示。
(3)专用 LLM 代理:任务分工,提高输出鲁棒性,但复杂代码下准确性仍下降。
(4)与外部工具集成:如 LangChain 简化异步调用,RAG 向量化代码上下文,但需针对代码语义的专门方法。
挑战 3:LLM 内在局限性
LLM 对数据变化和对抗攻击缺乏鲁棒性,同时在漏洞解释上表现不一致,输出具有随机性,即使识别正确也无法保证解释准确。
潜在方向:
(1)微调前沿 LLM:如 GPT-4、Claude3.5-Sonnet,通过扩大模型规模、训练数据和算力系统提升检测、分类和解释能力。
(2)漏洞特定微调:针对特定漏洞类型(如内存问题、注入漏洞)微调,提高检测精度。
(3)仓库自适应微调:在特定项目上微调,理解项目特定编码模式,提高大规模项目检测能力。
(4)集成学习与领域自适应预训练(DAPT):结合多模型预测,利用公共和领域数据优化识别能力。
(5)自适应学习机制:通过反馈循环和周期性再训练更新知识,提高鲁棒性,优化提示配置和学习率。
挑战 4:高质量数据集匮乏
当前数据集存在数据泄露、标签错误、规模小和覆盖范围有限等问题。
潜在方向:
(1)数据集质量与范围提升:构建高质量测试集、整合多个验证样本,支持仓库级分析。
(2)可扩展性与长尾漏洞处理:通过数据增强生成稀有漏洞样本,提高 LLM 检测低频事件的能力;结合 CWE 分类结构优化漏洞优先级处理。
信息来源:通大智能软工课题组 陈翔


